Porting V-JEPA 2.1 to MLX
Table of Contents
Meta’s JEPA line of work has been one of the more talked about alternatives to the usual autoregressive framing. Instead of treating the world as a stream of tokens to reconstruct, JEPA models aim to predict useful latent representations. In video, that matters: if the goal is understanding motion, actions, and physical dynamics, predicting in representation space is often a better fit than predicting pixels.
The original V-JEPA [1] made that argument concrete for video. V-JEPA 2 [2] pushed the idea further toward understanding, prediction, and planning in the physical world. V-JEPA 2.1 [3] then sharpened the representation side again, with denser visual features, multi-modal image/video tokenization, and better support for tasks that care about spatial structure rather than only global pooled semantics.
I wanted to understand the JEPA stack better by tracing one serious model all the way from the upstream PyTorch implementation to a faithful local MLX port. At the same time, I was curious about models performance on my local device (M1 MacbookPro).
That leads directly to the goal of this project: build a faithful MLX port of the V-JEPA 2.1 encoder, verify it against the upstream PyTorch checkpoints, and see whether it is actually usable on Apple silicon. MLX is a good fit for that experiment because it is built for Apple silicon, and because moving from PyTorch to MLX is approachable as the MLX api is intentionally made similar to PyTorch.
Code can be found here.
Project scope
On Apple silicon, MLX is the natural way to get good local performance without fighting the stack. It is a fast, native array framework for ML on Apple silicon devices.
So the project was built in the following order:
- Port the encoder inference path for the public V-JEPA 2.1 checkpoints.
- Verify that the MLX port matches the upstream PyTorch outputs.
- Only then benchmark the two backends on the same normalized inputs.
This repository does not port the full V-JEPA training recipe. For JEPA models, a large part of the final quality comes from the training setup: the objective, masking design, data, optimization choices, and the surrounding recipe. This repo ports encoder inference, parity checks, and benchmarking.
The repository now contains:
- an MLX encoder port for the V-JEPA 2.1 base
ViT-B/16(80M parameters) and largeViT-L/16(300M) checkpoints. It consists of the visual transformer and some extra layers. - one shared preprocessing path for image and video inputs
- a PyTorch reference path that wraps the upstream
facebookresearch/vjepa2code - parity tooling that compares PyTorch and MLX encoder features directly
- a benchmark harness that measures forward pass latency on PyTorch CPU, PyTorch MPS, and MLX
Translating the model to MLX
Translating code from PyTorch to MLX was straightforward, replacing import torch.nn as nn with import mlx.nn as nn, followed by minor tweaks.
Frontier LLMs are very good at translating code from one language/framework to another and Codex was able to do most of it on its own. However, I went manually through the modelling code to make sure I understand the model architecture.
Results and discusison
Parity
To compare implementation parity, both backends receive the same preprocessed tensor, and the resulting encoder features are compared with cosine similarity, max absolute error, and mean absolute error.
Cosine similarity should land very close to 1, and the absolute errors should stay small enough that the two implementations are effectively producing the same encoder features for practical use.
We can see that for the all four tested cases, those requirements are met.
| Model | Input | Cosine similarity | Max abs error | Mean abs error |
|---|---|---|---|---|
ViT-B/16 | image | 0.9999999999545541 | 0.0005054474 | 0.0000061885 |
ViT-B/16 | video | 0.9999999994269152 | 0.0032711029 | 0.0000198340 |
ViT-L/16 | image | 0.9999999999829752 | 0.0003022552 | 0.0000067038 |
ViT-L/16 | video | 0.9999999997930077 | 0.0044296980 | 0.0000214287 |
Speed benchmarking
The benchmark setup is intentionally narrow because the goal is to compare model forward performance across backends without mixing in preprocessing, decoding, or other I/O noise:
- forward pass only
- preprocessing measured separately and excluded from headline latency
2warmup iterations10timed iterations- one model and one input configuration per run
- the same preprocessed tensor reused across all targets within a run
All benchmarks in this post were run on an Apple M1 Max machine with 32 GB of memory.
Backend policy:
- PyTorch CPU:
torch.compile(model) - PyTorch MPS: eager mode
- MLX:
mx.compile(model)
PyTorch MPS is kept in eager mode because torch.compile fails in the upstream RoPE path.
Resolution of both images and videos used is 384 x 384.
For video,four clips lengths are benchmarked: 8, 16, 32, and 64 sampled frames.
Images
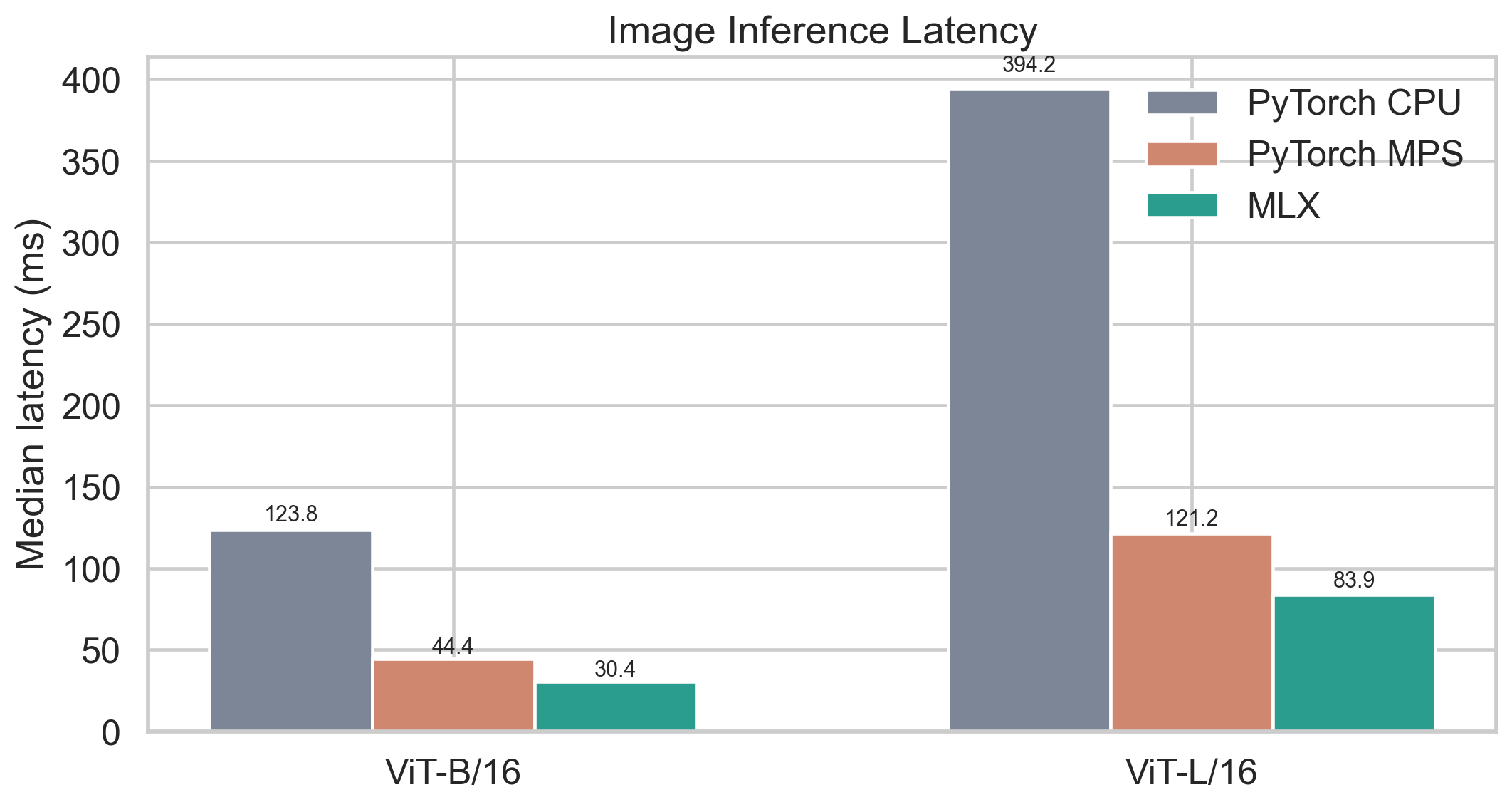
For image inference, MLX is the fastest backend in both model sizes. PyTorch MPS is still much better than CPU, but MLX has a clear lead.
Compared with PyTorch MPS, MLX reduces latency by about 31% for both ViT-B/16 and ViT-L/16.
Videos
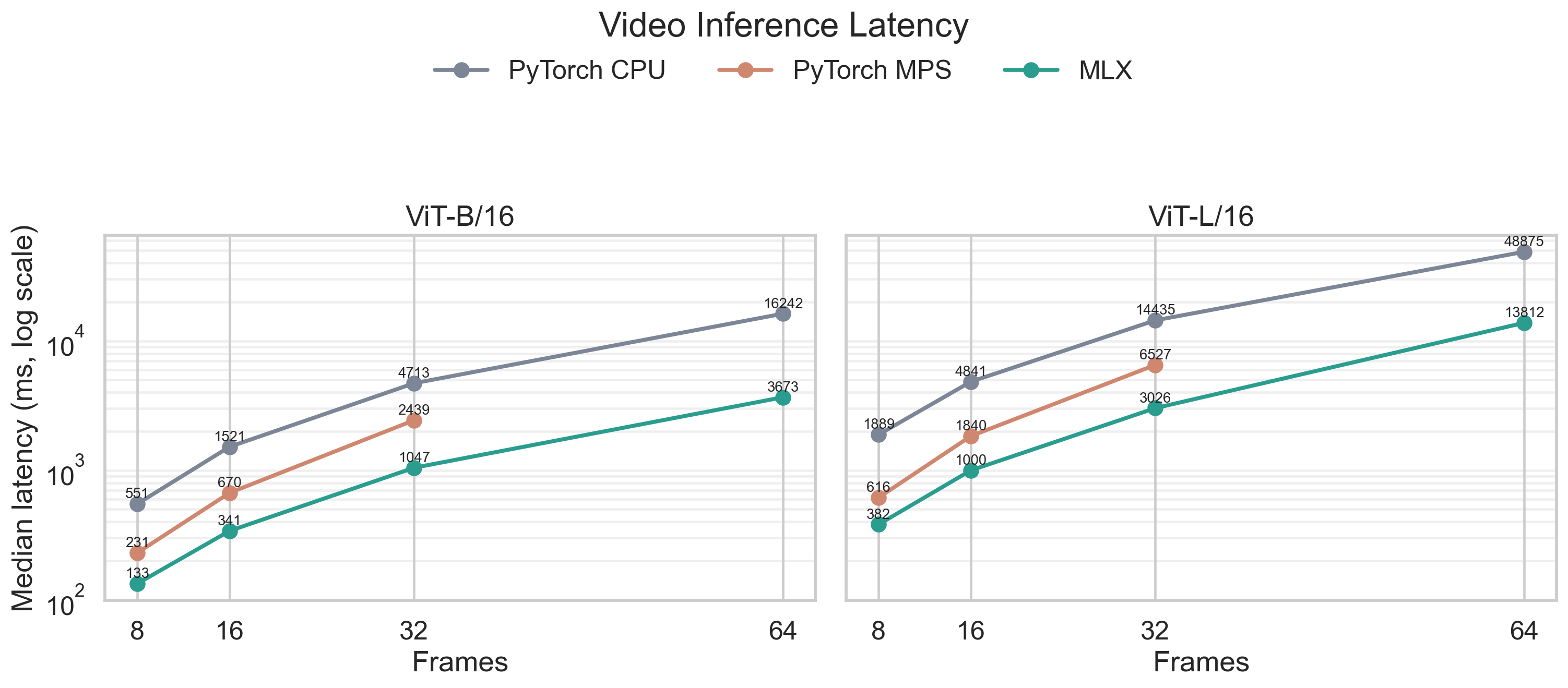
MLX stays in front across all tested cases, reducing latency by about 38-57%, depending on model size and frame count. The scaling behavior is as expected: more frames cost more time, and ViT-L/16 is slower than ViT-B/16.
In the longest, 64-frames case, MPS implementation goes out of memory. CPU and MLX finish successufully. This is a huge win for MLX as it shows that it’s not just faster, but also more memory friendly.
Conclusion
This project shows that the V-JEPA 2.1 encoder can be ported to MLX. The port is both faster and requires less memory than the original implementation.
Running the model locally with MLX opens up the door for many privacy focused applications, for which we don’t want to send data to the cloud - for example analysis of echocardiographic videos (EchoJEPA [6]).
While this implementation is efficient, it’s just a part of the V-JEPA stack. Training code and recipes haven’t been ported and are much less feasible, as training of JEPA models is done on multiple GPUs.
Next steps could be testing out the biggest variants of V-JEPA modles (1B params) on a machine with more memory, running ablations on newer Apple Sillicon chips, creating a comprehensive V-JEPA mlx library that combines this work with V-JEPA 2 port or running PCA on the extracted features to get some nice visuals of them.
If you have some ideas, feel free to contribute to the repo 😊
Credits
- EchoJEPA is the motivation for this work
- gaarutyunov/vjepa2-mlx was a useful reference point for parts of the MLX port.
References
[1] V-JEPA: Revisiting Feature Prediction for Learning Visual Representations from Video
[2] V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
[3] V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
[4] facebookresearch/vjepa2
[5] gaarutyunov/vjepa2-mlx